This blog will teach us about Layer-wise Sequential Unit-Variance (LSUV), layer normalization, and batch normalization. This blog is based on lesson 17 of the FastAI course.
LSUV is a straightforward technique for initializing weights. Layer norm and batch norm do not initialize weights before the training, but they help the model train by modifying the statistics of the weights.
First, we import libraries and do required setups.
class GeneralRelu(nn.Module):def__init__(self, leaky=None, sub=0., max_val=None):super().__init__()self.relu = nn.ReLU() if leaky isNoneelse nn.LeakyReLU(leaky)self.sub = subself.max_val = max_valdef forward(self, x): x =self.relu(x) x -=self.subifself.max_val isnotNone: x.clamp_max_(self.max_val)return x
def conv(ni, nf, ks=3, stride=2, act=None): res = nn.Conv2d(ni, nf, stride=stride, kernel_size=ks, padding=ks//2)if act isnotNone: res = nn.Sequential(res, act())return res
LSUV came from All you need is a good init. This has a very complicated name, but it is a straightforward idea. The good thing about this paper is that it does not have complicated math like other papers, so it is suitable for beginners to read. Simply put, regardless of what kind of activation layer we use, we can initialize weights correctly for training. Here, initializing correctly means making a mean of zero and a standard deviation of one, which allows us to train fast.
For different activation layers, we have to use variety of initialization techniques. For instance, when using relu, we use kaiming initialization, and if there is no activation layer, we can just use Xavier init. Instead of using different activation methods for them, we can just use LSUV to initialize the weights. Let’s look at the pseudo code from the paper and create it ourselves.
Here is the pseudo code from the paper:
Pre-initialize network with orthonormal matrices as in Saxe et al. (2014)
for each layer L do
while |Var(BL) − 1.0| ≥ Tolvar and (Ti < Tmax) do
do Forward pass with a mini-batch
calculate Var(BL)
WL = WL / sqrt(Var(BL))
end while
end for
L is convolution or full-connected layer
Var(x) takes variance of input x.
BL is output blob from L.
Tolvar is variance tolerance
Ti is current trial. Incremented every loop.
Tmax is max trial
WL is weights
sqrt(x) takes square root of input x.
According to the paper, we call the model on a batch of data to find the standard deviation of the weights. Then, we divide the weight by the standard deviation to set them closer to 1. If it is not close enough, we repeat the process until it is within our tolerance, Tolvar. We also increment Ti in each loop, and if it reaches Tmax, we stop the loop. However, in practice, it never reached Tmax. That’s it. Let’s implement it ourselves.
To get the statistics of the data, we use Pytorch hooks. For our initialization function, we take act for the activation function and conv for convolutional layers. So, we calculate statistics from act output and update conv weights. After initialization, we remove hooks to clean up.
def good_init_hook(hook, m, inp, outp): x = to_cpu(outp) hook.mean, hook.std = x.mean(), x.std()
The initialization worked, and our model trained well. However, it requires many lines of code. So, let’s create a callback! Because we only want to fit once, we track whether the model’s been fitted. We also have an option to initialize bias or not. We do not need bias when we use batch normalization or layer normalization later.
class LSUVCB(Callback):def__init__(self, bias=True):self.fit_ =Falseself.bias = biasdef before_fit(self, learn):ifnotself.fit_:self.fit_ =True model = learn.model grs = [o for o in model.modules() ifisinstance(o, GeneralRelu)] convs = [o for o in model.modules() ifisinstance(o, nn.Conv2d)]for m, m_in inzip(grs, convs): init = good_init ifself.bias else good_init_no_bias init(model, m, m_in, xb, tol=0.001)
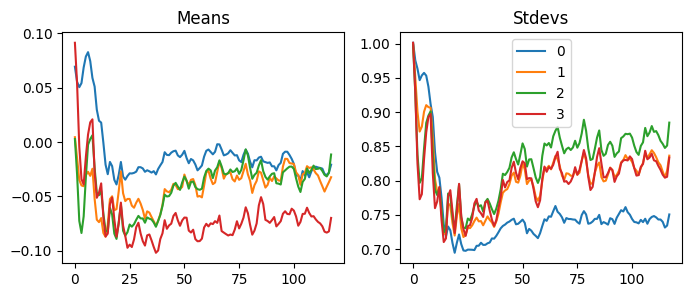
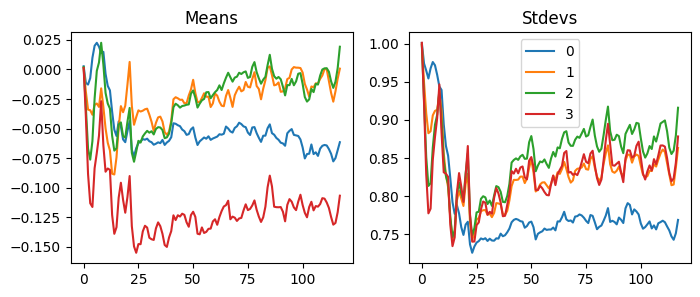
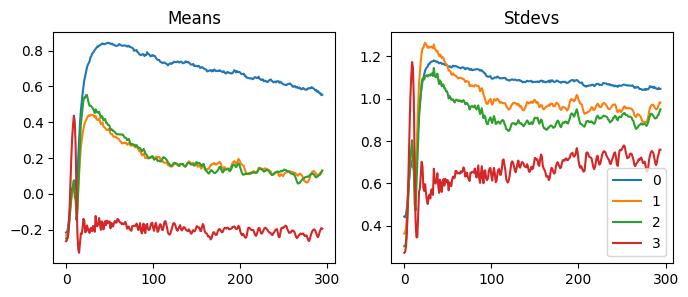
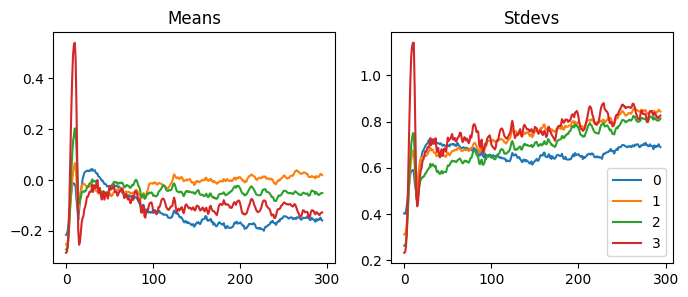
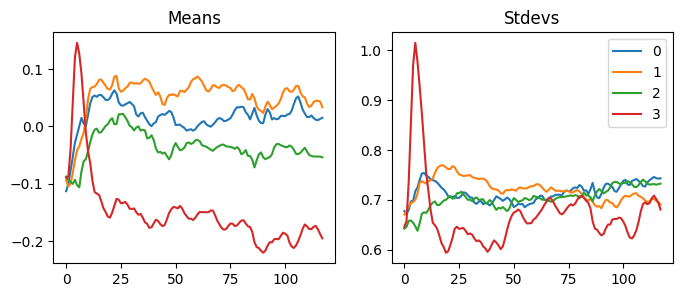
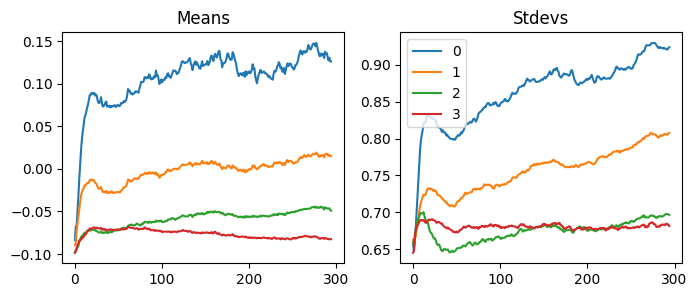
With our LSUVCB, we can do the same thing very easily. When we look at the statistics of the activations, we can see the activations move to the mean of zero and the standard deviation of one.
Layer Normalization
Before we start looking at batch normalization, we will look at layer norm, a simpler version of batch norm. Layer Normalization by Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton is math-heavy and challenging to understand. However, the code is straightforward.
Although batch norm performs very well, it has a couple of limitations. It was computationally expensive, cannot be used for recurrent neural networks, and cannot have models with small batch sizes. To fix these issues, layer norm uses fewer parameters to train with a more straightforward design.
What does LayerNorm do? It has learnable parameters, self.mult and self.add. For each batch, it calculates means and standard deviations over the channels, heights, and weights for each batch size. Then, we normalize the weights to a mean of zero and a standard deviation of one. However, this might not be the ideal place for the the weights for training. That’s where self.mult and self.add come in to shift the weights to better places. To define new parameters in Pytorch, we use nn.Parameter.
We also take eps as a parameter. This prevents weights from getting too big when the standard deviation gets too low. dummy parameter does not do anything here, but it will be used for batch norm.
To use LayerNorm and BatchNorm, we must slightly modify the conv. It takes norm and bias parameters because these techniques do not need bias because we normalize each batch using self.mult and self.add. Basically, self.add acts as bias.
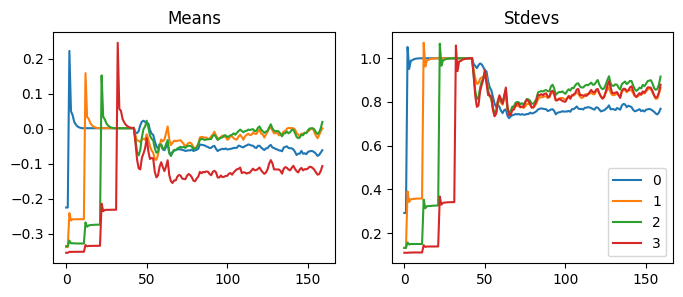
We did not initialize the weights before training. However, layer norm normalizes every batch, so it is optional. But let’s try initializing the weights before we train.
I think this paper is awesome how the authors thought covariate shift was the problem of training and found a way to manage it. They normalized each batch, which helped the model to train. It also had learnable parameters that can shift and scale the distribution to more easily trainable distribution.
We can think of the neural net as a chef and the transformation as a server. A chef can take orders, cook, and serve at the same time if the restaurant is not busy. However, as more customers come in, a server can help so that the chef can focus on cooking. Instead of the neural nets to find magic parameters for the minimum loss, we help them with finding the best distribution for the weights using those learnable parameters.
However, batch norm makes training epochs slower. Also, this is quite a complicated algorithm with learnable parameters and has more complex inference as we will see later.
More in depth of the paper:
Those who want to skip this part can still understand its importance and the code without learning the underlying math. However, we will dig into some math and equations for those who are curious.
The paper defines Internal Covariate Shift as the change in the distributions of internal nodes of a deep network during training. Why is this a problem? To train fast, the inputs of each layer have to have zero means and unit variances without correlation according to Efficient Backprop by LeCun et al. However, when we train, statistics of the inputs change due to updating parameters.
First thing the authors tried to fix this issue is to update the statistics after the stochastic gradient descent step to train by normalization. However, the bias grew too much because the optimization did not know about the normalization. So, the normalization had to be part of the gradient step process.
So, they suggested using the whole data to normalize. However, this is too expensive, so they use mini-batch statistics assuming these represent statistics for the whole data.
The paper says, a layer with d-dimensional input \(\mathbf{x}=(x^{(1)}\ldots x^{(d)})\), we normalize each dimension
where \(\operatorname {E}[x^{(k)}]\) is expected value and \(\operatorname {Var}[x^{(k)}]\) is variance over the training data set. The expected value is an average, and there is more information on wikipedia.
Then, we apply the transformation to each dimension:
This is almost the same thing as equation (1). For this one, we omit (k) for simplicity and readability. Instead of using \(\operatorname {E}\) or \(\operatorname {Var}\), we use Greek letters here for some reason. \(\mu_B\) (mu) represents an average over the batch, \(\sigma^{2}_B\) (sigma) is a variance over the batch. \(\epsilon\) (epsilon) is used for numerical stability just in case our variance gets too small. After normalization, we scale and shift using the equation (2).
Now, let’s move on to Algorithm 2 in section 3.1. This section is all about inference. For inference, we use the population (the whole thing) instead of using batches to calculate means and variances. We use moving averages to calculate these.
In Algorithm 2, the first part is training, and the second is inference. Although number 10 says, “process multiple training mini-batches \(B\), …” we calculate these during the training. The last step was a bit confusing to me when I first encountered this:
\[ y = \frac{\gamma}{\sqrt{\operatorname{Var}[x]+\epsilon}}\cdot x + (\beta - \frac{\gamma\operatorname{E}[x]}{\sqrt{\operatorname{Var}[x]+\epsilon}}) \tag{4}\]
This is the same as the normalization step combined with scale and shift in Algorithm 1. We can rewrite equation (4) as the following:
That’s it. Now let’s take a look at the code from FastAI course:
class BatchNorm(nn.Module):def__init__(self, nf, mom=0.1, eps=1e-5):super().__init__()# NB: pytorch bn mom is opposite of what you'd expectself.mom,self.eps = mom,epsself.mults = nn.Parameter(torch.ones (nf,1,1)) # Used for both training and inference (gamma)self.adds = nn.Parameter(torch.zeros(nf,1,1)) # Used for both training and inference (beta)self.register_buffer('vars', torch.ones(1,nf,1,1)) # Only used for inference (Var[x])self.register_buffer('means', torch.zeros(1,nf,1,1)) # Only used for inference (E[x])def update_stats(self, x): m = x.mean((0,2,3), keepdim=True) # NCHW v = x.var ((0,2,3), keepdim=True)self.means.lerp_(m, self.mom) # Weighted averageself.vars.lerp_ (v, self.mom)return m,vdef forward(self, x):ifself.training:with torch.no_grad(): m,v =self.update_stats(x)else: m,v =self.means,self.vars x = (x-m) / (v+self.eps).sqrt()return x*self.mults +self.adds
The update_stats method calculates means and variances over channels/features of the convolutional layer. This is because we want the same feature map to be normalized similarly. This is also where the moving average takes place to save vars and means.
Technically, batch and layer norms do not need initialization because the layers are normalized in each batch/epoch. These also normalize layers, so they do not need as much normalization as others. We will learn about different normalization techniques later, but these are techniques that prevent the models from overfitting.
Batch normalization also allows us to use a higher learning rate.
Pros: - Higher learning rate. - Regularization. - Less epochs for better results.
Cons: - Slower training. - Cannot be used for RNN. - Cannot use very small batch sizes.
Conclusion
This blog taught us about LSUV, layer norm, and batch norm. They are all similar to each other. LSUV normalizes before training, and others normalize each batch. Layer norm is a simpler version of batch norm. We also dug deeper into the papers. The batch norm is widely used, and reading the paper will benefit the deep learning journey.
Reading papers is difficult, but it is a helpful skill to learn new things. It may be challenging at first and perhaps impossible depending on which paper or what prerequisite readers have, but it will be easier to read.