In this blog, we will talk about Residual network (Resnet). Resnet came from Deep Residual Learning for Image Recognition by Kaiming He et al. We have seen Kaiming/He initialization from the author before.
Before we get into the code, let’s see what resent is and why it works conceptually.
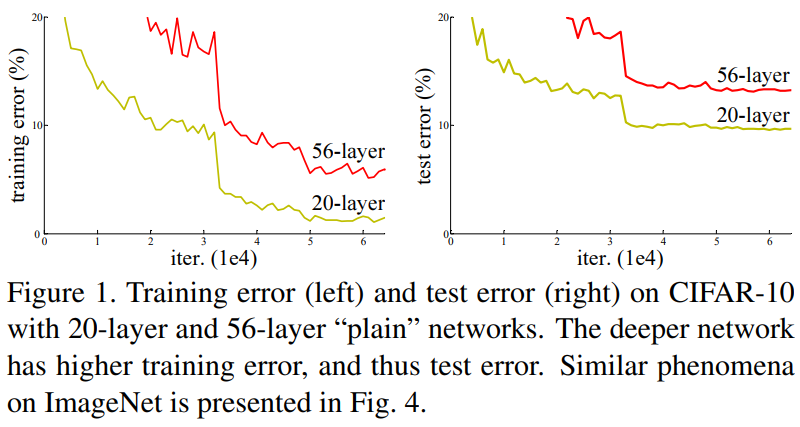
In the paper, the team found that deep neural networks performed worse than shallow neural networks. In theory, a deeper net should capture more details and perform better. The problem persisted even when they built the deep neural net from the shallow one appended with additional layers. If appended layers did nothing, the deeper net should perform as well as the shallower net. However, these appended layers hampered the training.
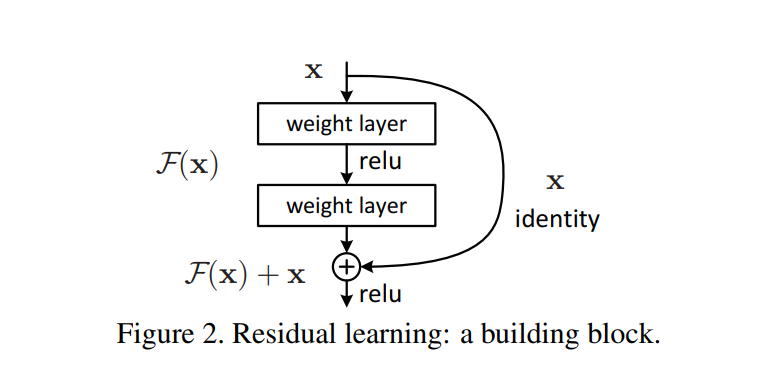
Instead of appending layers at the end of the shallow net, they used deep residual learning framework. So, there is an input, x, and two layers, F. Applying the layers F on x results in F(x), and we add x to this, resulting in F(x) + x. Here, we can consider F as the additional layers we appended at the end of the shallow net in the previous approach. However, because we are doing F(x) + x, x acts as a stabilizer. It stabilizes F(x) if there is no improvement. x is called identity and stabilizes the training.
Let’s get into the code. We can define F(x) + x as a ResBlock. We define _conv_block, which has two convolutional layers. The first layer changes the input from ni to nf with stride one, and the second layer uses the given stride without activation.
In ResBlock, we use nn.AvgPool2d if stride is two and a convolutional layer with kernel size one to match the shape of x and F(x) when there is a stride and/or ni is different from nf.
By looking into the input and output shapes from the layers, we can look at layers and their shapes quickly. By using the summary, it is more convenient to build a model.
def print_shapes(hook, m, inp, outp):print(m.__class__.__name__, inp[0].shape, outp.shape)
model = get_model()learn = TrainLearner(model, dls, F.cross_entropy, cbs=[SingleBatchCB(), DeviceCB()])with Hooks(model, print_shapes) as h: learn.fit(1)
We can patch it into the Learner and use it as a class method.
@fc.patchdef summary(self:Learner): res ='|Module|Input|Output|Num params|\n|--|--|--|--|\n' num =0def _f(hook, m, inp, outp):nonlocal res, num num_params =sum(o.numel() for o in m.parameters()) res +=f'|{m.__class__.__name__}|{tuple(inp[0].shape)}|{tuple(outp.shape)}|{num_params}|\n' num += num_paramswith Hooks(self.model, _f) as hook: self.fit(1, train=False, cbs=[SingleBatchCB()])print('Total number of params:', num)if fc.IN_NOTEBOOK:from IPython.display import Markdownreturn Markdown(res)else:print(res)
learn.summary()
Total number of params: 1247362
Module
Input
Output
Num params
ResBlock
(1024, 1, 28, 28)
(1024, 8, 28, 28)
680
ResBlock
(1024, 8, 28, 28)
(1024, 16, 14, 14)
3632
ResBlock
(1024, 16, 14, 14)
(1024, 32, 7, 7)
14432
ResBlock
(1024, 32, 7, 7)
(1024, 64, 4, 4)
57536
ResBlock
(1024, 64, 4, 4)
(1024, 128, 2, 2)
229760
ResBlock
(1024, 128, 2, 2)
(1024, 256, 1, 1)
918272
Sequential
(1024, 256, 1, 1)
(1024, 10, 1, 1)
23050
Flatten
(1024, 10, 1, 1)
(1024, 10)
0
GlobalAvgPool
Our model only works on images with 28 by 28 pixels. To use images with higher resolutions, we can use GlobalAvgPool. It simply averages the last two dimensions into one by one. We can then use flatten to remove these dimensions. Then, we can use a linear layer to create an output layer.
class GlobalAvgPool(nn.Module):def forward(self, x): return x.mean((-1, -2))
We can also add number of flops into the summary. Number of flops provides the number of operations. The way we calculate flops here is not very accurate, but it still tells us roughly how compute intensive the layer is.
[(o.shape, o.numel()) for o in nn.Linear(2, 8).parameters()]
[(torch.Size([8, 2]), 16), (torch.Size([8]), 8)]
@fc.patchdef summary(self:Learner): res ='|Module|Input|Output|Num params|Flops|\n|--|--|--|--|--|\n' n_params, n_flops =0, 0def _f(hook, m, inp, outp):nonlocal res, n_params, n_flops num_params =sum(o.numel() for o in m.parameters())*_, h, w = outp.shape num_flops =sum(_flops(o, h, w) for o in m.parameters())/1e6 n_params += num_params n_flops += num_flops res +=f'|{m.__class__.__name__}|{tuple(inp[0].shape)}|{tuple(outp.shape)}|{num_params}|{num_flops:.2f}|\n'with Hooks(self.model, _f) as hook: self.fit(1, train=False, cbs=[SingleBatchCB()])print('Total number of params:', n_params)print('Total number of flops:', n_flops)if fc.IN_NOTEBOOK:from IPython.display import Markdownreturn Markdown(res)else:print(res)
Total number of params: 1226882
Total number of flops: 4.675826000000001
Module
Input
Output
Num params
Flops
ResBlock
(1024, 1, 28, 28)
(1024, 8, 28, 28)
680
0.51
ResBlock
(1024, 8, 28, 28)
(1024, 16, 14, 14)
3632
0.70
ResBlock
(1024, 16, 14, 14)
(1024, 32, 7, 7)
14432
0.70
ResBlock
(1024, 32, 7, 7)
(1024, 64, 4, 4)
57536
0.92
ResBlock
(1024, 64, 4, 4)
(1024, 128, 2, 2)
229760
0.92
ResBlock
(1024, 128, 2, 2)
(1024, 256, 1, 1)
918272
0.92
GlobalAvgPool
(1024, 256, 1, 1)
(1024, 256)
0
0.00
Flatten
(1024, 256)
(1024, 256)
0
0.00
Linear
(1024, 256)
(1024, 10)
2570
0.00
Conclusion
In this blog, we learned about Resnet. As we have seen from the code, it is straightforward. It is conceptually easy to understand why it works as well. We also learned about creating a summary with module names, input and output shapes, number of parameters, and number of flops. It allows us to look at the big picture of the model. It’s also helpful when creating a model and debugging to look at the layers’ shapes.