In this blog, let’s explore some initializing methods on weights to train better. Our model can train well with a good initialization because close to all the activations become zeroes. Thanks to the Pytorch hooks we learned from the last blog, we can look into activation statistics as we try different techniques. This blog is based on lesson 17 of the FastAI course.
First, we import libraries and do required setups.
Mounted at /content/drive
/content/drive/MyDrive/Colab Notebooks
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 179.2/179.2 kB 3.4 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 519.6/519.6 kB 7.4 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 115.3/115.3 kB 10.5 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 194.1/194.1 kB 16.9 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 134.8/134.8 kB 11.5 MB/s eta 0:00:00
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 302.0/302.0 kB 23.2 MB/s eta 0:00:00
We’ve been using Hugging Face Datasets, but let’s try Pytorch’s datasets this time. This way, we do not have to convert the Pyarrow format into tensors every time we use the data. So, it is faster for slow CPUs like Kaggle or Google Colab.
After training, we want to look at the statistics of the weights all the time, so we make a callback for it. This way, we do not have to call stat.plot_stats after training.
class ShowStatsCB(Callback):def after_fit(self, learn): astats.plot_stats(figsize=(8, 3))
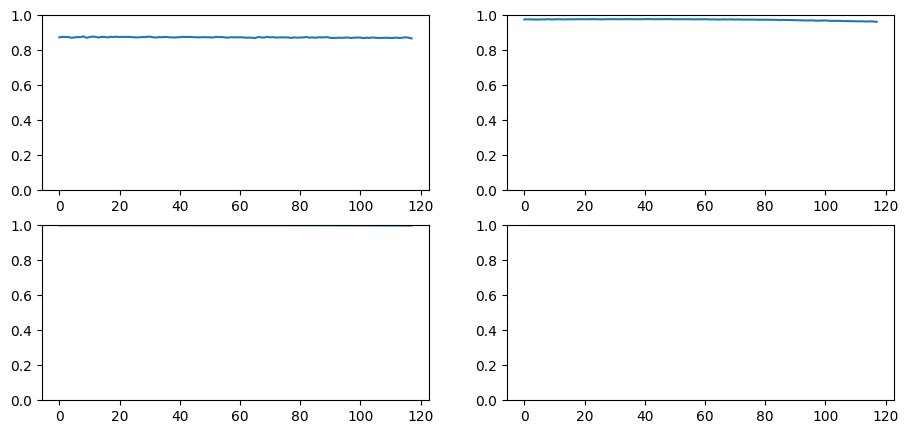
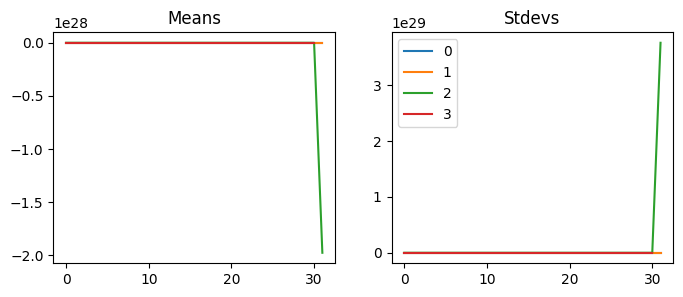
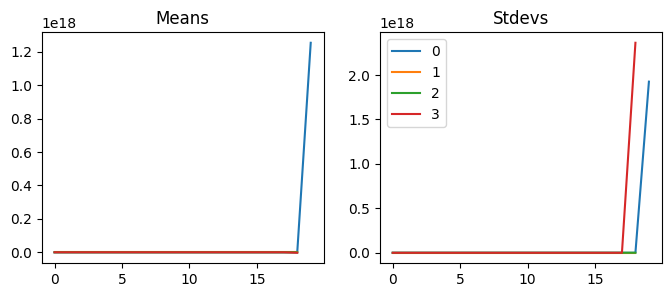
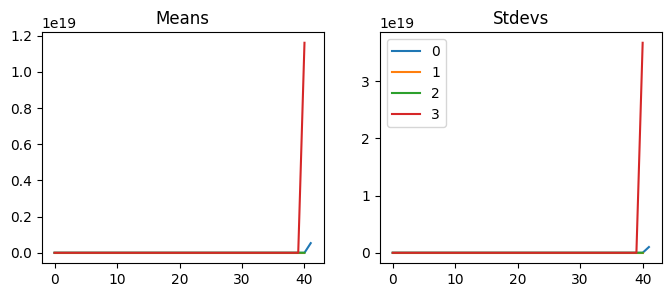
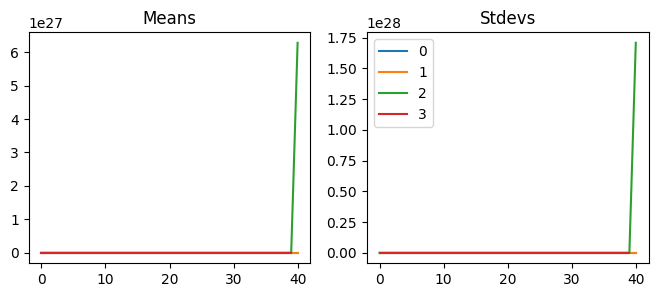
This isn’t good. Reducing the learning rate does not do anything because it is not training at all. Looking at activation statistics, we can see that they are very close to zeros. We can also check the dead chart; almost all the activations are zeroes. So what’s going on here?
Matrix multiplications
So, let’s see what happens if we repeatedly perform matrix multiplication on a given matrix. If we execute this fifty times, all the values become nans, which means they are too large for the computers. Therefore, if we have a model with fifty layers, we would get a model full of nans. Do you know how we can fix this issue? We can perform matrix multiplications with smaller values to prevent values from exploding.
x = torch.randn(200, 100)for i inrange(50): x = x @ torch.randn(100,100)x[0:5,0:5]
According to Understanding the difficulty of training deep feedforward neural networks written by Xavier Glorot and Yoshua Bengio, we can initialize weights by multiplying them by the square root of the number of inputs to stabilize calculations. The paper used uniform distribution, but we can use normal distribution, which still works. This trick also appears in Efficient Backprop by Yann Lecun et al. section 4.6 initializing the weights. In both papers, the goal is to make the mean of zero and the standard deviation of 1.
x.mean(), x.std()
(tensor(0.00), tensor(0.61))
First, we initialize weights, w, with normal distribution with the mean of 0 and the standard deviation of 1. Then, we multiply w by \(1/\sqrt{n_{in}}\) where \(n_{in}\) is a number of inputs. \[w = w * \frac{1}{\sqrt{n_{in}}}\]
In other words, w is normally distributed with the mean of 0 and the standard deviation of \(1/\sqrt{n_{in}}\) or the variance of \(1/n_{in}\).
\[w \sim \mathcal{N}(0, \frac{1}{n_{in}})\]
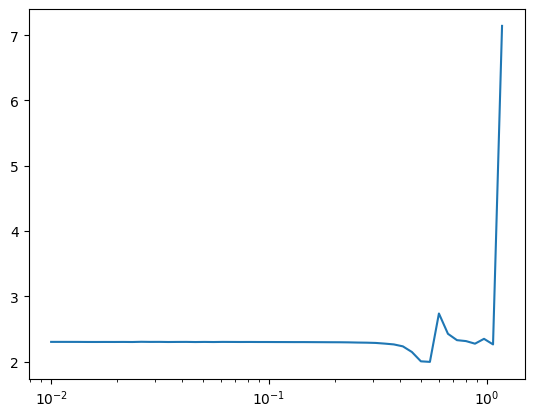
How did they come up with this number? We can try to find mean and standard deviations ourselves from matrix multiplications. When we change the size, sz, of the input matrix, x, the standard deviation is pretty close to the sz. We can try different sizes.
def get_stats(epochs =100, sz =100, init =1., act =None, seed =None):if seed isnotNone: set_seed(seed) mean, sqr =0., 0.for _ inrange(epochs): x = torch.randn(64, sz) * init a = torch.randn(sz) y = x @ aif act isnotNone: y = act(y) mean += y.mean().item() sqr += y.pow(2).mean().item()return mean / epochs, sqr / epochs
get_stats()
(-0.04464139200747013, 99.57821556091308)
get_stats(sz =200)
(-0.005759633108973503, 197.81238624572754)
get_stats(sz =1000)
(0.7149963945150375, 1005.3396026611329)
That is very cool. We can keep the mean of 0 and the standard deviation of 1 and train deep neural networks! However, we cannot use this initialization because we will use the relu activation function, which messes up the statistics! What do you think we should do?
Where w is the weights are distributed as a normal distribution with the mean of 0 and the standard deviation of \(\sqrt{2/n_{in}}\) or the variance of \(2/n_{in}\) where \(n_{in}\) is the number of inputs.
get_stats(act=nn.ReLU())
(4.105671746730804, 52.16908494949341)
get_stats(sz =200, act=nn.ReLU())
(5.568780157566071, 97.80967510223388)
get_stats(sz =1000, act=nn.ReLU())
(12.306093001365662, 485.7778285217285)
Compared to Glorot init, standard deviations are halved. We can also see that the mean is not zero anymore. What’s going on? We are left with only positive numbers because relu clips all the negative numbers. Therefore, we cannot have the mean of zero anymore. The only way to get a zero mean is to have all the zeroes as activations, but the standard deviation will also be zero.
Now that we can use an initialization method, let’s try to improve our previous model with Kaiming init.
model = get_model()model.apply(lambda m: print(type(m).__name__));
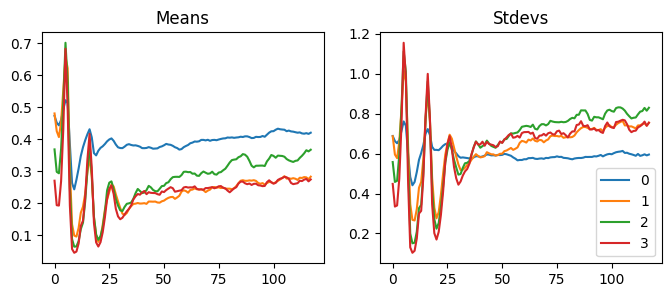
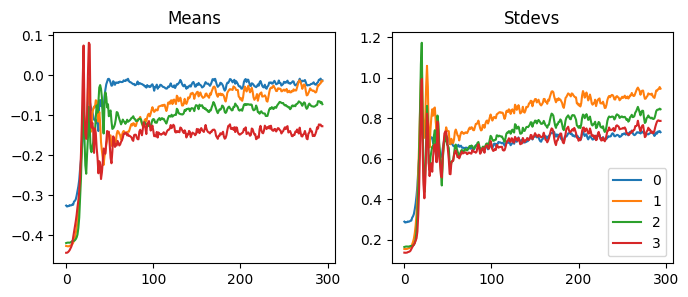
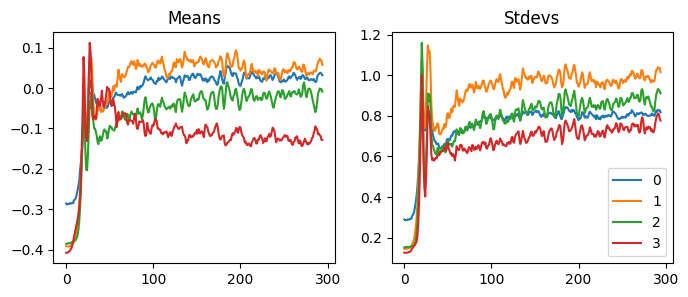
We can apply Kaiming init with apply method. We can see that it worked by looking at the mean and the standard deviation of the activations before and after initialization.
We now create flexible GeneralRelu because the mean was not zero with Kaiming init. This version of relu allows us to subtract a number and do a leaky relu. Instead of clamping negative numbers, leaky relu uses a negative slope.
class GeneralRelu(nn.Module):def__init__(self, leaky=None, sub=None, max_val=None):super().__init__()self.relu = nn.ReLU() if leaky isNoneelse nn.LeakyReLU(leaky)self.sub =0.if sub isNoneelse subself.max_val = max_valdef forward(self, x): x =self.relu(x) x -=self.subifself.max_val isnotNone: x.clamp_max_(self.max_val)return x
Let’s look at what it looks like by plotting this function.
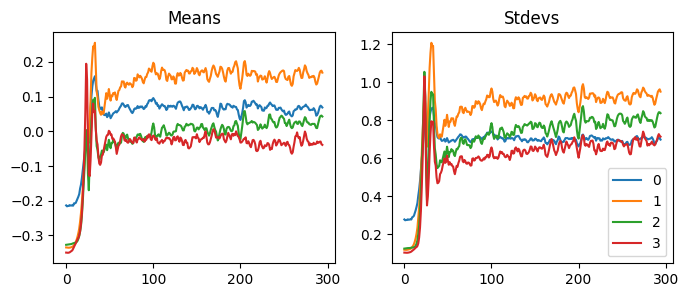
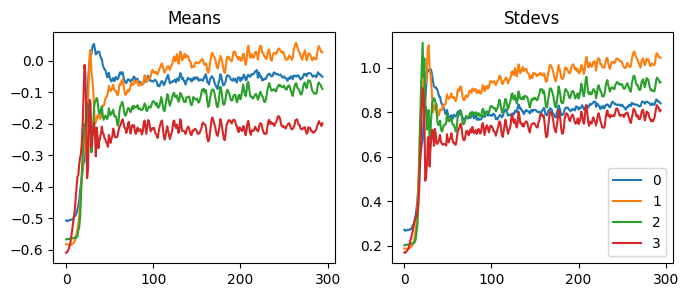
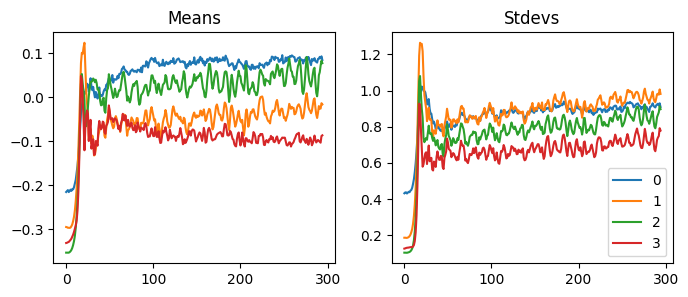
When we use GeneralRelu(.05, .9), the mean and the std are similar to others, but the activations collapse. So, do the mean and the standard deviations not matter at all? Let’s keep trying other values.
Reducing the mean to closer to zero did not always work out. Also, using different seed values sometimes made the model untrainable. For instance, using .2 and .4 with seed one does not work, but it works well without seed or using other seed values. Also, depending on the seed, the accuracy fluctuates a lot.
We can hypothesize that if we use an immense value for the leaky relu, the function becomes too linear, and the model cannot calculate helpful predictions. If we pay close attention to the statistics, we can see that all the mean and the standard deviation shifted early in the training to find a good spot.
Some good values to use are (.1, .4), (.5, .7), and (.2, .4), but there can be other values.
In this blog, we learned about different initialization techniques, such as Glorot/Xavier init, Kaiming/He init, and trying GeneralRelu with different arguments. We also learned how important it is to have the mean of zero and the standard deviation of one for our activations. Now that we have learned Kaiming init, we can train deeper networks without vanishing or crashing activations.
Next time, we will learn about Layer-wise Sequential Unit-Variance (LSUV), layer normalization, and batch normalization.